How does CCM19 Bot handle-traffic?
CCM19's tariff model is based not only on the number of domain-visits but also on page views. We are therefore frequently asked whether and how bot-accesses to the websites are counted as page views in CCM19.
In principle, page views that are clearly attributable to bots are not counted as views. To achieve this, we have taken the following measures:
- For each call, we check the user-agent and if it identifies itself as a search engine (Google, Bing, Yandex etc.), the call is not counted.
- We also inform search engines via robots.txt that our tool should not be crawled. Search engines that adhere to this are therefore also not counted.
- We also keep a constantly growing filter list with IP-addresses of bots that we have identified over the years. This mainly includes crawlers from SEO-tools and hosters. Calls from bots on this filter list are also not counted.
This allows us to recognize and filter out the majority of bot-traffic, so that bot-accesses are not significant for most customers.
How to identify bot-traffic in your account
In rare cases, however, it can still happen that bot-traffic is also counted in your CCM19-account. It is usually easy to recognize in the statistics by an extremely high number of views where no interaction with the banner is recorded. Example:
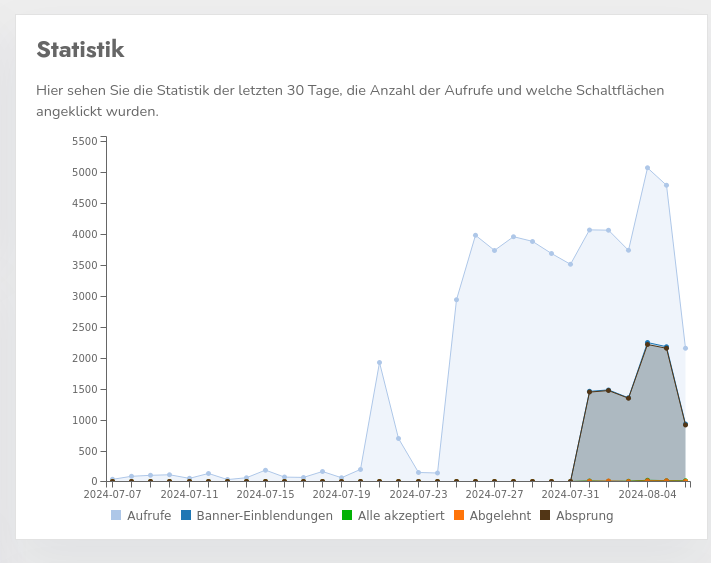
Sometimes regular spikes can also appear in the statistics. These clearly indicate a crawler that scans the entire page at a fixed interval and thus generates artificial traffic:
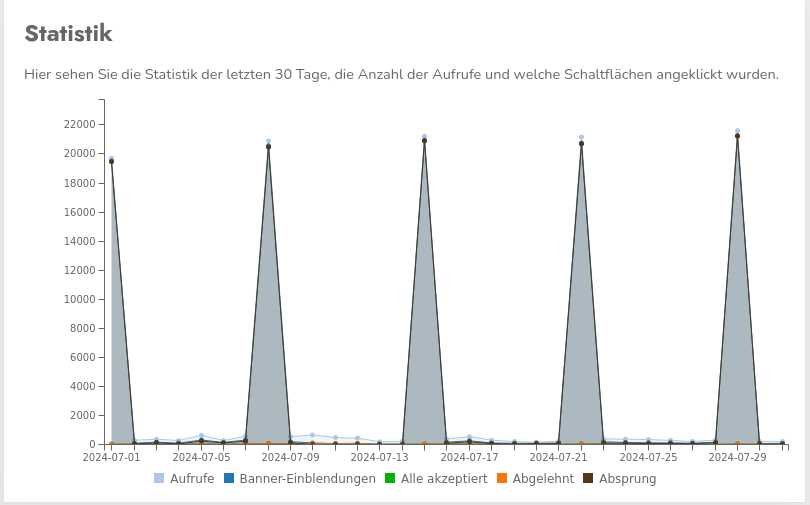
These bots currently fall through our cracks because they do not identify themselves as bots, ignore robots.txt or use proxy-servers and therefore do not have a fixed IP-address.
What you can do against bot-traffic
If you notice increased traffic from bots that are putting a noticeable strain on your-quota in CCM19, you can analyze the log files on your server and try to identify the problematic bots. You can do two things with this information:
- Prevent the bot from continuing to access your website via the server-configuration.
- If you do not want to disable bot-access in principle because you want to have your website crawled regularly by an SEO-tool, for example, let us know the user-agent or the IP of the bot. We will then check whether we can add this bot to our filter list.